The Rise of the Data Intelligence Platform: Architecting Lakehouse AI for Scale
The Rise of the Data Intelligence Platform: Architecting Lakehouse AI for Scale
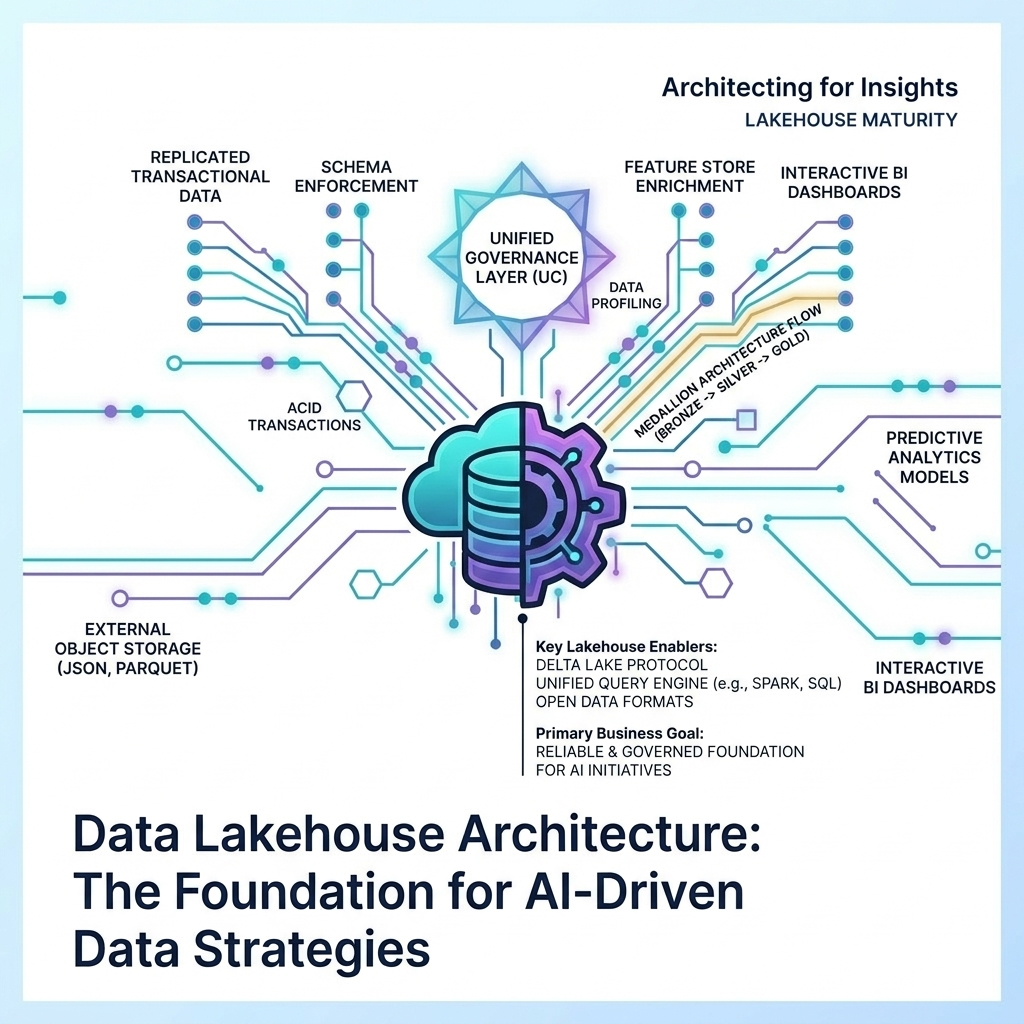
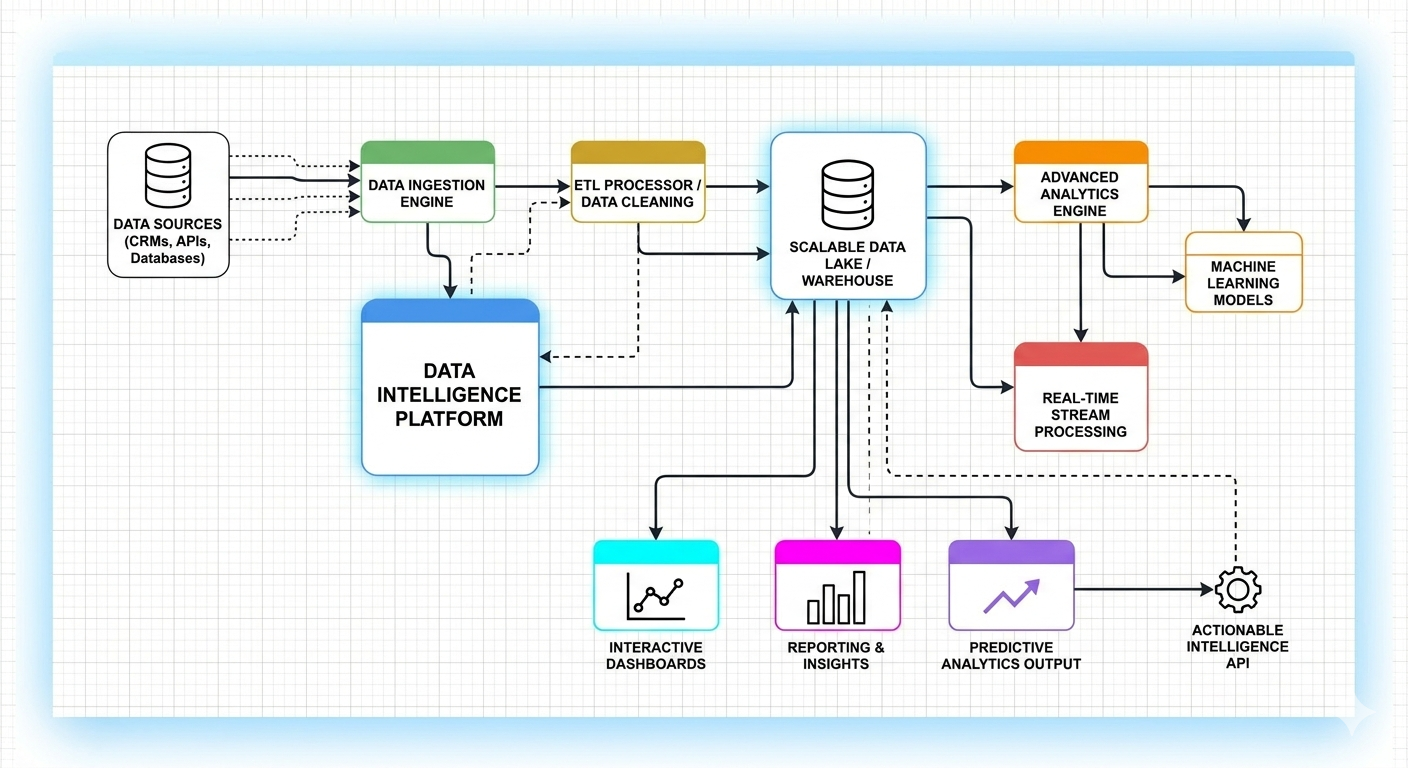
In the current technological landscape, the distinction between a “data company” and an “AI company” is rapidly evaporating. For senior leadership and architects alike, the challenge has shifted from simply storing data to creating a mechanism that feeds high-quality data into machine learning models with minimal friction. This is where the concept of the Lakehouse, specifically within the Databricks ecosystem, is evolving into what I refer to as a “Data Intelligence Platform.”
Having spent years navigating complex, production-grade engineering environments, I’ve observed a recurring failure point in AI initiatives: the “Data-Model Gap.” Organizations often treat data engineering and AI development as two separate kingdoms. Data is extracted, transformed, and then—critically—moved to a separate environment for model training. This movement introduces latency, governance risks, and the dreaded “training-serving skew.”
The Lakehouse architecture addresses this by enabling model training and deployment directly on the data lake. In my view, this data-centric approach to AI is the only way to achieve sustainable ROI in the Generative AI era.
The Mechanism of Integrated Governance
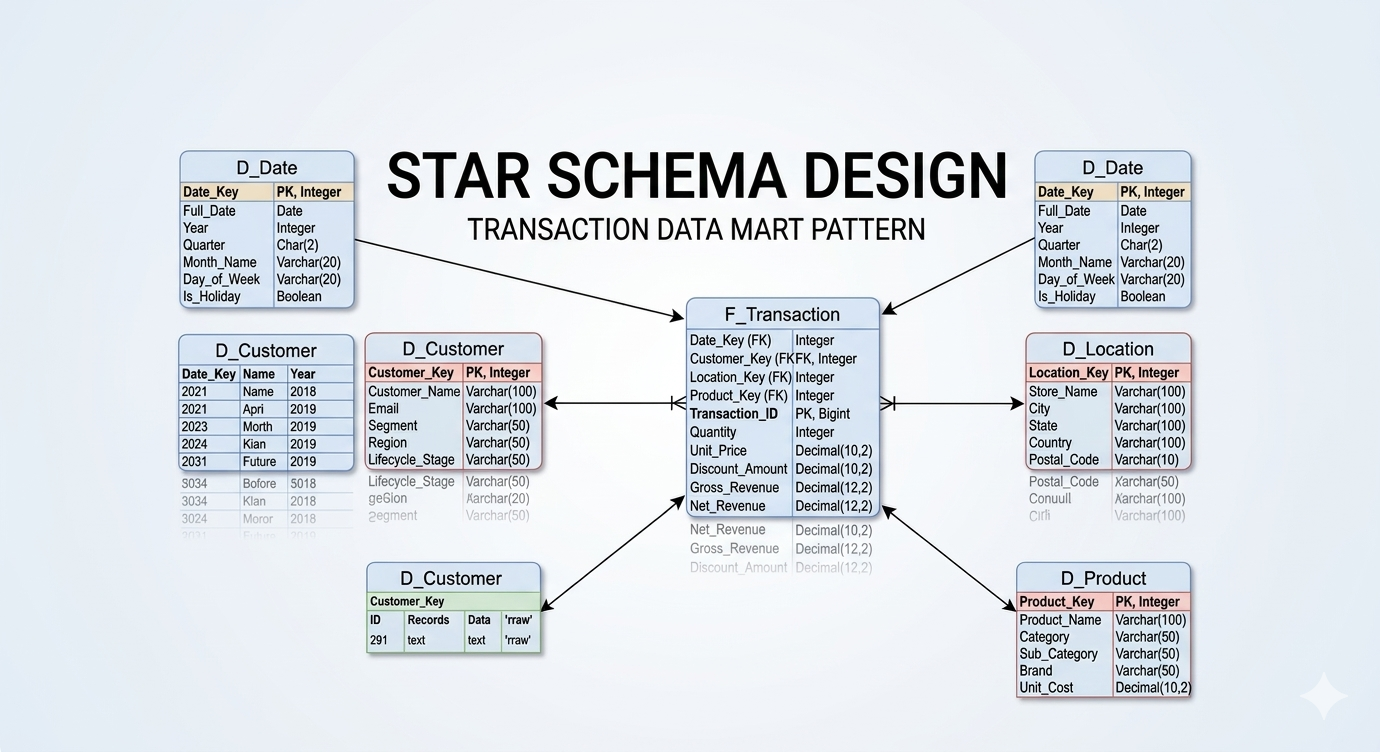
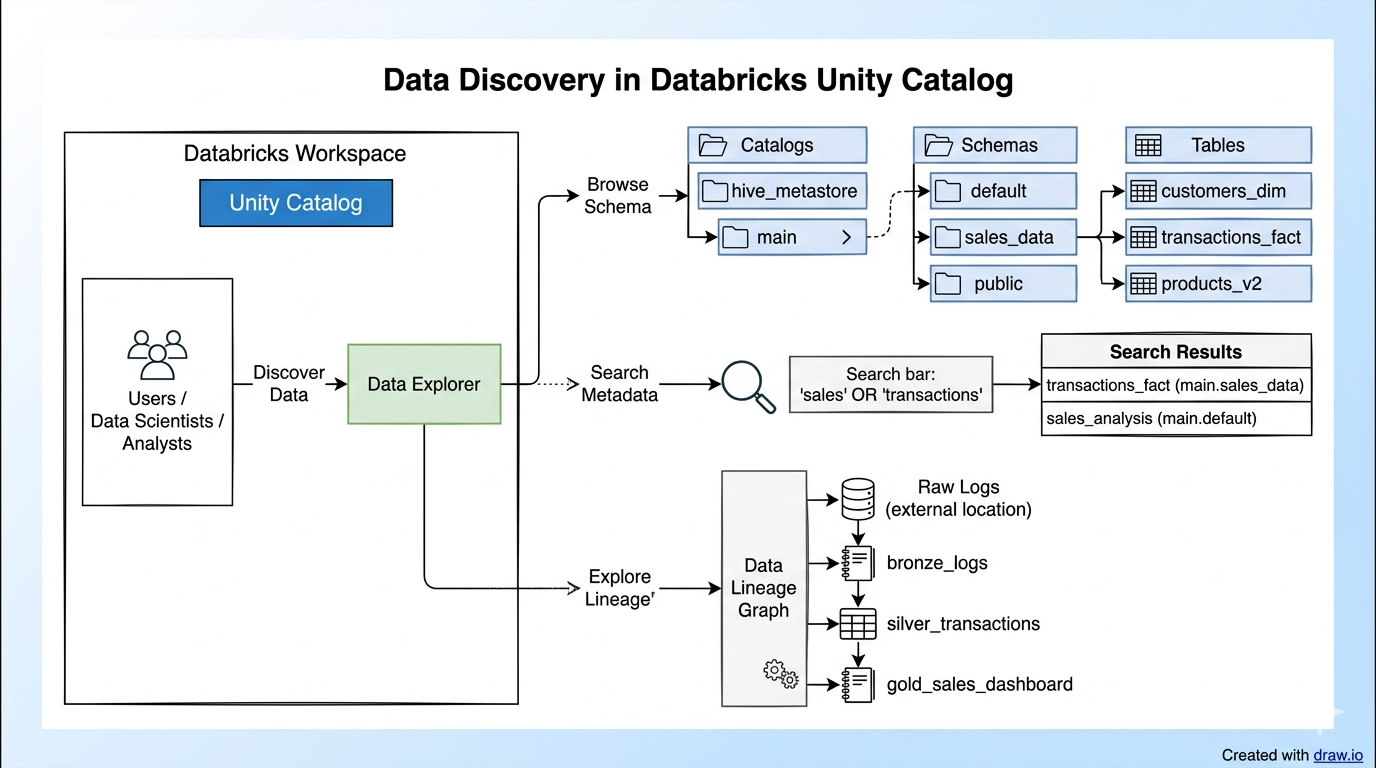
One of the most significant structural shifts in the Databricks platform is the consolidation of assets under the Unity Catalog. Specifically, the merger of the Model Registry and Feature Store into a single governance layer is a masterstroke for operational stability.
Historically, tracking which version of a dataset was used to train which version of a model was a manual, error-prone process. Thereafter, maintaining consistency when that model went into production was another hurdle. With Unity Catalog, we now have a unified “lineage” that tracks data from its raw state to the features it generates, and finally to the models that consume them.
Specifically, this enables Consistent Governance:
- Unified Tracking: Both data and AI assets (models, features, functions) share the same security and audit trails.
- Lineage Visibility: If a source table is updated, you can instantly see which downstream models might be affected.
This isn’t just a technical convenience; it’s a risk mitigation strategy. For VCs and Directors, this level of oversight is what differentiates a “pilot project” from an “enterprise-grade solution.”
Scaling AI Without the Infrastructure Headache
A common concern I hear during technical audits is the sheer cost and complexity of GPU resources. While it’s true that infrastructure costs for large-scale AI are significant, the Lakehouse AI suite provides several “levers” to optimize these expenses.
Databricks has introduced GPU-powered model serving and Vector Search, which together can improve performance by up to 10x compared to traditional, fragmented architectures. This reduces the Total Cost of Ownership (TCO) not just through raw performance, but by eliminating the need to maintain multiple disparate stacks for vector databases, feature stores, and inference engines.
Specifically, when calculating TCO, one must account for the “hidden” costs of data movement. In a traditional stack, the cost of egressing data from a warehouse to an AI serving environment—plus the labor costs of managing that pipeline—often exceeds the cost of the compute itself. By consolidating these functions, we create a more resilient liquidity buffer for technical budgets.
Furthermore, features like AutoML for LLMs provide a “point-and-click” interface for fine-tuning generative models. While I always recommend deep architectural reviews for flagship models, this accessibility allows internal teams to upskill and experiment without needing a PhD in machine learning for every minor task.
Bridging the Performance Gap: Model Serving and Monitoring
Deployment is where most AI strategies fail. Specifically, the latency between a data update and a model’s reaction can be a dealbreaker for real-time applications. Databricks addresses this through Feature and Function Serving, which serves computations via a REST API. This prevents “training-serving skew” by ensuring the exact same logic used during training is applied during inference.
Another critical component is the use of Inference Tables. These tables automatically log every request and response into Delta tables. From an engineering perspective, this is a mechanism for maintaining operational integrity—it gives you near real-time visibility into data drift and model performance.
In particular, these tables allow you to:
- Monitor Model Decay: As real-world data evolves, you can detect when a model’s performance begins to degrade (secular growth often masks these failures until they are critical).
- Audit AI-Driven Decisions: For regulatory compliance, having a historical record of every AI response is no longer optional.
- Continuous Feedback: Feed responses back into the training loop for continuous improvement.
The Strategic Frontier: Agentic Data Lakehouses
The move toward Agentic Data Lakehouses is the next major shift in the industry. This is where LLM agents are not just simple chatbots, but are integrated directly into your technical stack to provide insights, generate code, or even trigger workflows based on data trends.
I’ve started referring to this as the “Flagship” architecture for modern data estates. Very few organizations are currently connecting LLM Agents directly to Lakehouse architecture for BI, but those who do will have a massive competitive advantage. It moves the data platform from a passive repository to an active participant in business strategy.
The Strategic Takeaway
The transition from a Lakehouse to a Data Intelligence Platform means AI is no longer a “bolt-on” feature; it is embedded into the very layers of the stack. However, we must remain pragmatically skeptical: while the tools are maturing, the success of these systems still rests on the quality of the underlying data.
As I often tell my clients: a model is only as intelligent as the data it consumes. If your “medallion architecture” is messy, your AI will be too.
By consolidating your AI and data under a single governance and performance layer, you aren’t just building a technical solution; you’re building a structural asset that provides long-term value for your business.

{kind=link}